In the vast cosmos of data science, where algorithms promise to unlock everything from planetary movements to personal cycling prowess, there’s a critical challenge: ensuring our models aren’t just memorizing patterns, but truly understanding them. Imagine training an AI to predict your cycling performance, only to find it crumbles the moment you ride a new route. This isn’t just frustrating; it undermines the very purpose of data-driven discovery.
At Explore the Cosmos, our mission is to provide clear, data-driven insights, whether we’re analyzing complex systems or helping you optimize your cycling performance with tools like our privacy-first Apple Health Cycling Analyzer. Central to this mission is building trust in our analytical methods. That’s why today, we’re diving deep into cross-validation – a technique indispensable for building machine learning models that generalize effectively to unseen, real-world data.
The Core Challenge: Generalization, Not Memorization
Every machine learning model, from the simplest regression to the most intricate neural network, has one primary goal: to make accurate predictions or classifications on data it has never encountered during training. But here’s the catch: models learn from existing data. If not handled carefully, they can become too specialized, “memorizing” the training data’s noise and quirks rather than its underlying patterns. This is what we call overfitting.
Conversely, a model might be too simplistic, failing to capture the complexity within the data. This is underfitting. Both lead to unreliable results when faced with new information. For instance, if our cycling analyzer simply memorized your power output on one specific hill, it would fail to accurately assess your overall fitness or predict performance on a different incline. The true challenge lies in creating models that generalize – that adapt and perform well across diverse, new situations.
What is Cross-Validation? A Practical Definition
Cross-validation is a statistical method used to assess how well a machine learning model generalizes to an independent dataset. Think of it like this: if you’re a chef testing a new recipe, you wouldn’t just taste the batter once and assume it’s perfect. You’d bake several small samples, perhaps adjusting ingredients slightly each time, to ensure consistent quality across different batches. Cross-validation applies this same principle to data. It helps us check how well a model performs on new, unseen data by testing it on multiple different sets, reducing the likelihood of overfitting.
Why Cross-Validation is Indispensable for Reliable Insights
A simple train-test split, where data is divided once into a training set and a test set, can be misleading. The performance on that single test set might be unusually good or bad just by chance, especially with smaller datasets. This leaves us guessing about the model’s true real-world utility.
Cross-validation provides a far more robust and consistent estimate of model performance. It helps us:
- Estimate generalization performance reliably: By evaluating the model across multiple validation slices, we get a more dependable estimate of how it will perform on new data.
- Compare algorithms and settings consistently: It’s invaluable when choosing between different models, tuning hyperparameters, or comparing feature sets.
- Detect overfitting early: While it doesn’t prevent overfitting, it reveals it more reliably than a single split.
- Maximize data usage: Especially beneficial when working with limited data, as every data point gets a chance to be used for both training and testing.
Beyond Simple Train-Test Splits: The K-Fold Advantage
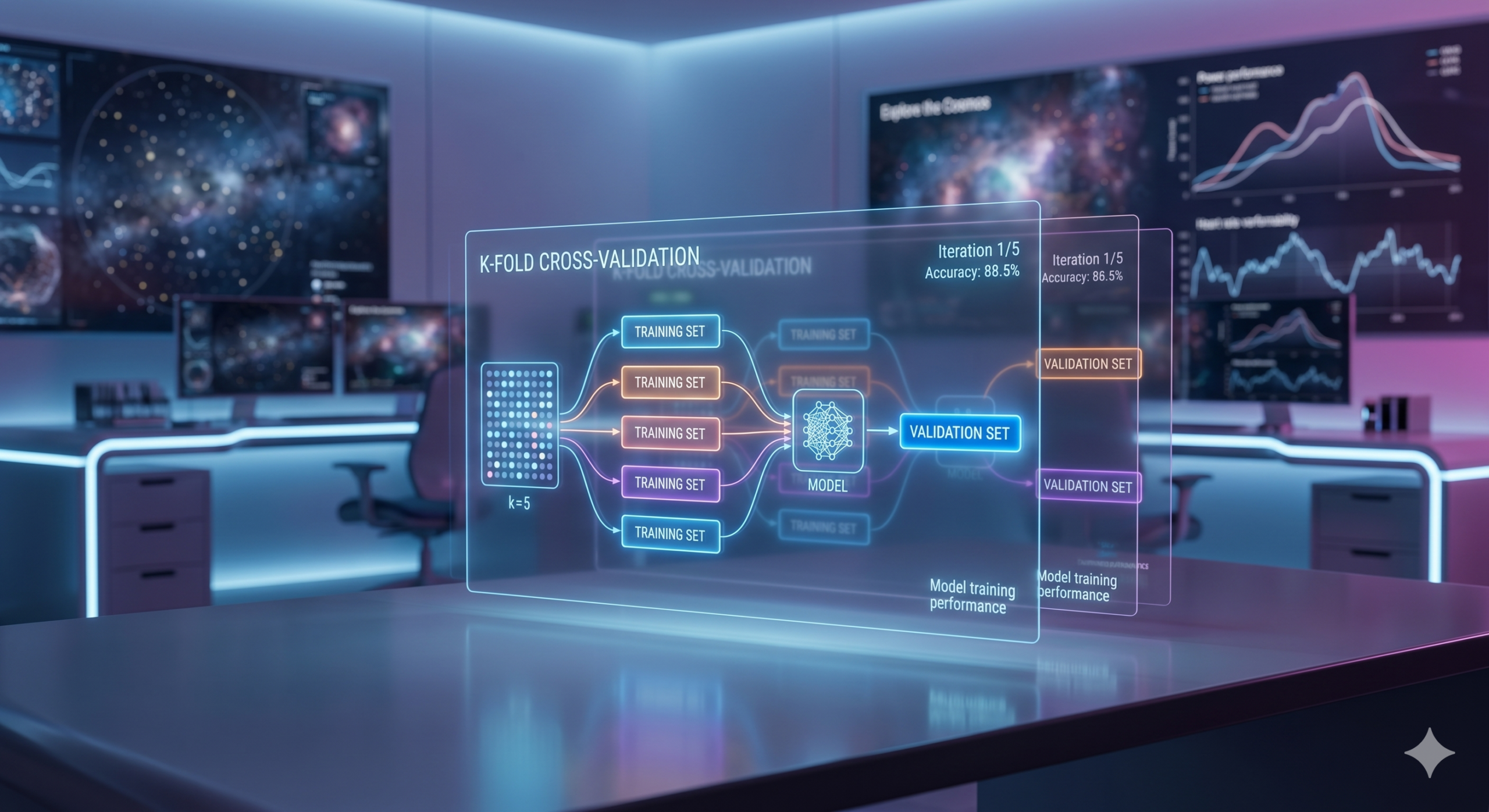
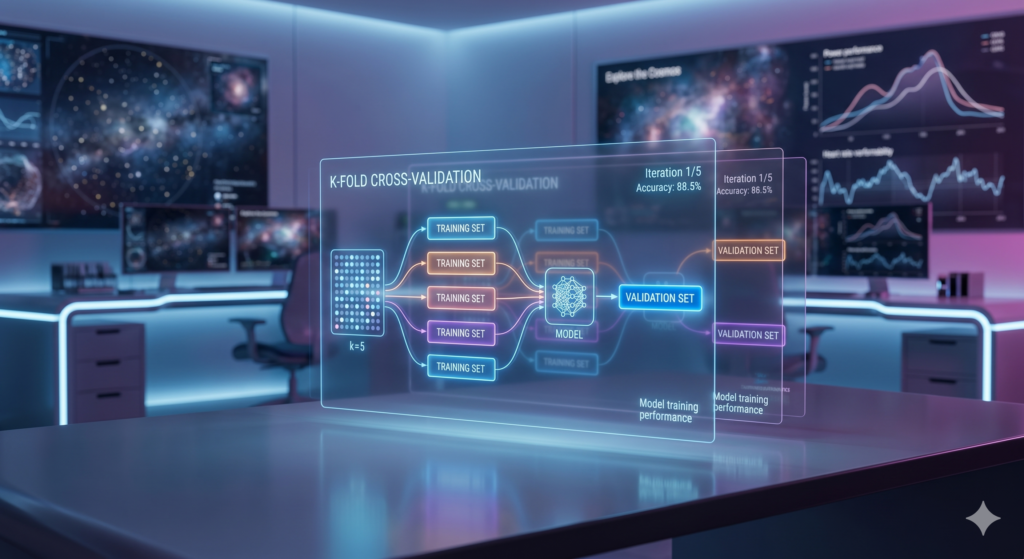
The most common and foundational cross-validation technique is K-Fold Cross-Validation. Here’s how it generally works:
- The entire dataset is divided into k equally sized “folds” or subsets. For instance, if k=5, the data is split into 5 parts.
- The model is trained k times (or “rounds”).
- In each round, a different fold is held out as the validation set, and the model is trained on the remaining k-1 folds.
- After k rounds, every fold has served as the validation set exactly once.
- The k performance scores (e.g., accuracy, mean squared error) from each round are then averaged to provide a single, more robust estimate of the model’s performance.
This process ensures that each data point gets to be part of both the training and validation sets, providing a comprehensive assessment.
Choosing the Right Cross-Validation Strategy: It’s Not One-Size-Fits-All
While K-Fold is a powerful default, the “right way” to cross-validate often depends on the specific characteristics of your data and problem. Modern data science in 2026 demands a nuanced approach, recognizing that different data structures require different validation strategies.
Standard K-Fold Cross-Validation
As discussed, this is the go-to for many general machine learning tasks, especially when data is limited, providing strong baselines. Practitioners often start with k=5 or k=10, balancing runtime with evaluation quality.
Stratified K-Fold Cross-Validation
When dealing with classification problems where one class is significantly less represented than others (an imbalanced dataset), standard K-Fold can inadvertently create folds where some classes are entirely missing or severely underrepresented. Stratified K-Fold ensures that each fold maintains the same proportion of class labels as the original dataset. This is crucial for producing realistic validation scores, particularly in classification tasks.
Leave-One-Out Cross-Validation (LOOCV)
This is an extreme form of K-Fold where k is equal to the number of data points. Each data point is used as a validation set exactly once, with the rest used for training. While computationally expensive, LOOCV can be useful for very small datasets where maximizing the training set size for each iteration is critical. However, its high variance can sometimes make it less stable than K-Fold.
Time Series Cross-Validation (Walk-Forward Validation)
This is a critically important technique for sequential data, such as our cycling performance metrics, stock prices, or sensor readings. Standard random shuffling breaks the inherent temporal order, leading to “data leakage” where future information might inadvertently influence training.
Walk-forward validation, a key practice in 2026, simulates real-world deployment. The model is trained on past data and evaluated on subsequent, unseen future data. As time advances, the training window expands (or slides), and the model is continuously retrained and re-evaluated. This mirrors how a model would actually be used in production and is essential for reliable time series forecasting.
Common Pitfalls and How to Avoid Them (The “Right Way” Part)
Even with the best intentions, cross-validation can go wrong, leading to misleadingly optimistic performance estimates. In 2026, avoiding these pitfalls is paramount for building AI systems that hold up under real-world complexity.
Data Leakage: The Silent Model Killer
This is arguably the most insidious problem. Data leakage occurs when information from the validation or test set inadvertently “leaks” into the training process, giving the model an unfair advantage. A major trend in 2026 highlights that the *entire modeling process* can overfit the validation set if not careful, leading to “meta-overfitting”.
- Preprocessing Outside Folds: A common mistake is performing data preprocessing steps (like scaling features, imputing missing values, or feature selection) on the entire dataset *before* splitting it into folds. This leaks information from the validation folds into the training process.
- The Right Way: All preprocessing steps must be applied independently within each training fold and then transformed using the parameters learned from that training fold onto its corresponding validation fold. This ensures that the model only sees data it would realistically encounter at inference time. Robust MLOps pipelines are designed to enforce this.
Insufficient Folds or Inappropriate Splits
The choice of k matters. Too small a k can lead to higher bias in performance estimation, while too large a k increases computational cost and can sometimes lead to more variable fold scores. Moreover, simply using standard K-Fold for data with inherent dependencies (like time series or grouped data) is an inappropriate split.
- The Right Way: Consider the dataset size, model training cost, and risk of leakage when choosing k. For small datasets, a larger k (like 10) might be preferable to maximize training data in each round. For time-dependent data, always use specialized time series validation techniques like walk-forward validation. If samples are grouped (e.g., multiple readings from the same cyclist), use Group K-Fold to ensure samples from the same group appear together in either the training or validation set, but not both, preventing leakage.
Ignoring Data Dependencies and “Meta-Overfitting”
As highlighted by recent discussions, simply having a validation set doesn’t guarantee unbiased evaluation. If we iteratively tune hyperparameters or adjust architectures based on the validation set’s performance, we can implicitly overfit to it – a phenomenon called “meta-overfitting”. The validation set stops being a neutral judge and becomes part of the optimization loop.
- The Right Way: For a truly honest evaluation, especially during hyperparameter tuning, consider Nested Cross-Validation. This involves an “outer” cross-validation loop for model evaluation and an “inner” loop for hyperparameter tuning. And for final reporting, always reserve a completely separate, untouched holdout test set that is only evaluated once after all model decisions are finalized. This ensures you get a clean, unbiased estimate of generalization performance.
The Future of Robust Model Evaluation in 2026 and Beyond
The landscape of data science is constantly evolving, and in 2026, the emphasis on robust model evaluation is stronger than ever. Several trends underscore our commitment at Explore the Cosmos to reliable, data-driven discovery:
- Rigorous Data Quality and Preprocessing within Folds: The push for high-quality data and meticulous preprocessing continues to be a cornerstone. Best practices in 2026 dictate that data quality assessments and all data manipulation (scaling, imputation, feature engineering) must happen *within* each cross-validation fold. This ensures that the evaluation is truly representative of how the model will perform on new, raw data, and prevents data leakage that could artificially inflate performance metrics.
- Specialized Cross-Validation for Complex Data Structures: The recognition that “one size fits all” no longer applies to cross-validation is a major theme. For time-series data, like the kind processed by our Apple Health Cycling Analyzer, techniques such as walk-forward validation and careful comparison of expanding vs. sliding windows are essential to accurately gauge model robustness and prevent temporal leakage. This nuanced approach is vital for any field dealing with sequential or grouped data.
- Combating “Meta-Overfitting” with Nested Cross-Validation and Dedicated Test Sets: As models and tuning processes become more sophisticated, so too does the risk of “meta-overfitting,” where the entire experimental pipeline inadvertently adapts to the validation set. The prevailing best practice in 2026 involves using nested cross-validation or maintaining a strictly separate, untainted holdout test set for the final, honest evaluation of a model’s performance. This rigor is crucial for transitioning from impressive lab results to models that genuinely earn trust in the real world.
These trends reinforce the idea that model evaluation isn’t just a technical step; it’s a foundational discipline for building trustworthy AI solutions.
Cross-Validation in Practice: From Data Science to Cycling Performance
The principles of proper cross-validation aren’t abstract academic concepts; they are vital for practical applications across industries, including human performance analysis. Just as accurate model evaluation is critical for large-scale data science projects, it’s equally important when we analyze personal fitness data.
Our Apple Health Cycling Analyzer, for example, processes your exported Apple Health data directly in your browser. This privacy-first approach means your sensitive cycling data never leaves your device and is never uploaded to any server. This commitment to privacy goes hand-in-hand with our dedication to reliable data analysis. When we develop the underlying algorithms for calculating efficiency factor, heart rate drift, or VAM, principled validation techniques are integral to ensure that the insights you receive are not just accurate for one ride, but generalize across your diverse training sessions and conditions.
By understanding and applying cross-validation the right way, we ensure that the tools and articles we provide at Explore the Cosmos offer truly actionable, evidence-based insights, empowering your journey of discovery in data, science, and human potential.
Ultimately, a model that wins validation may impress the lab; a model that survives unseen data earns the world’s trust. This trust is what we strive for, always.
Leave a Reply