Imagine you’re training a starship’s navigation system, feeding it data from countless simulated journeys through known constellations. You want it to predict the safest and most efficient routes. Now, what if, instead of learning the general principles of celestial mechanics and avoiding known gravitational anomalies, the system starts memorizing the exact trajectory of every single simulated trip, including the minuscule, random fluctuations caused by cosmic dust particles? This is the essence of overfitting in machine learning, a phenomenon that can cripple even the most sophisticated algorithms, much like a starship commander relying on rote memorization rather than true understanding.
At Explore the Cosmos, our mission is to demystify complex topics like data science and machine learning, making them accessible through clear explanations and practical insights. We believe that understanding concepts like overfitting is crucial, whether you’re optimizing cycling performance with our Apple Health Cycling Analyzer or delving into the vastness of space through data. In this article, we’ll explore what overfitting is, why it’s a problem, and how we can prevent it, using visuals to make the abstract tangible.

The Goldilocks Problem: Finding the Perfect Fit
In machine learning, our goal is to build models that can learn patterns from data and apply them to new, unseen data. This ability to perform well on new data is called generalization. Overfitting occurs when a model learns the training data too well, to the point where it starts to capture not just the underlying patterns but also the noise and random fluctuations within that specific dataset. This leads to excellent performance on the training data but drastically poor performance when presented with new, unfamiliar data. It’s the “too smart for its own good” scenario, where memorization trumps understanding.
Conversely, underfitting happens when a model is too simple to capture the underlying patterns in the data. It fails to learn from the training data, resulting in poor performance on both the training and new data. Think of it as a starship navigation system that can only plot a straight line between two points, oblivious to any planets or asteroids in between.
The sweet spot, the “just right” scenario, is a well-fitted model. This model captures the essential patterns in the training data without getting bogged down by noise, allowing it to generalize effectively to new data. This balance is often referred to as the bias-variance tradeoff. An overfit model has low bias (it can capture complex patterns) but high variance (it’s highly sensitive to the training data), while an underfit model has high bias (it’s too simplistic) and low variance (it’s not very sensitive to the training data).
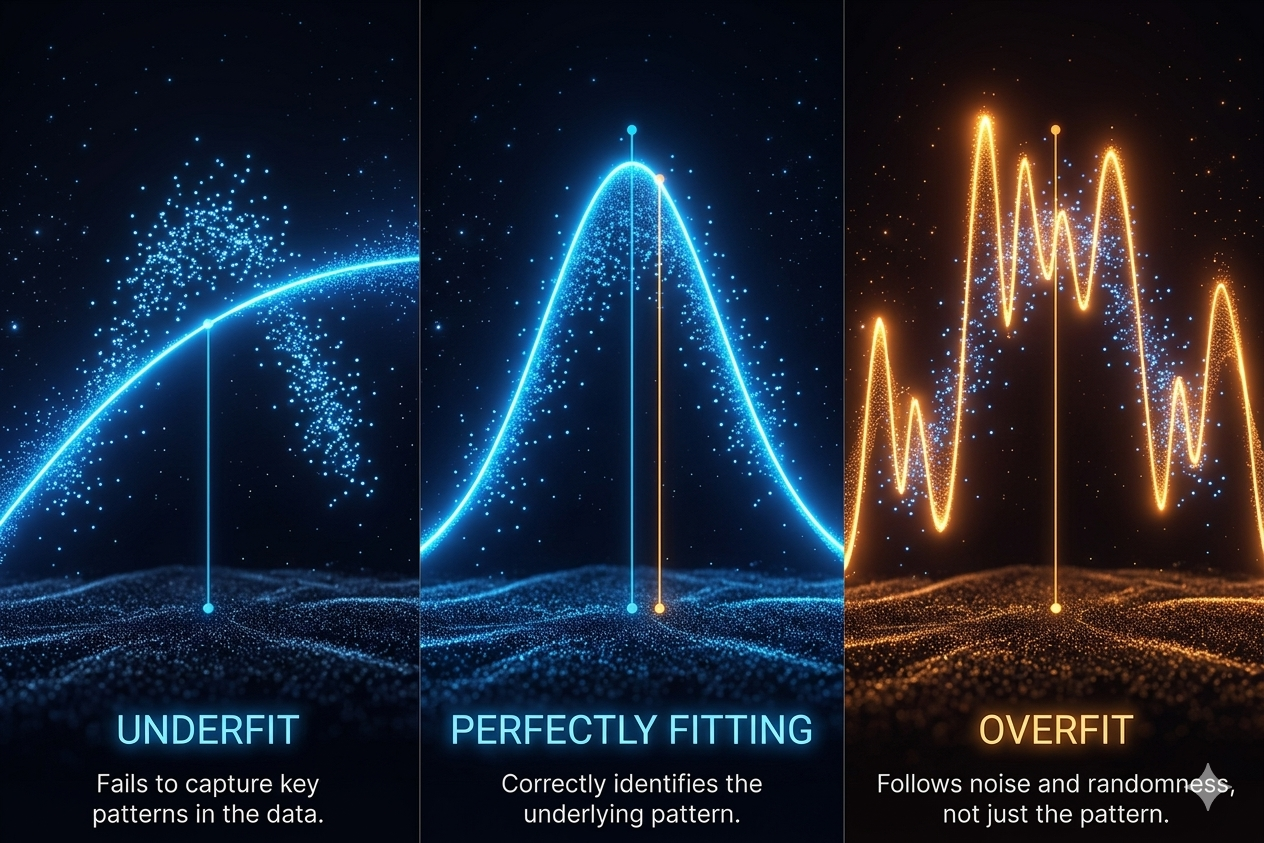
Visualizing the Problem: Underfitting, Overfitting, and the Ideal Fit
To truly grasp overfitting, let’s visualize it. Imagine we have a set of data points representing, perhaps, the relationship between training effort and cycling performance. Our goal is to draw a line that best represents this relationship.
- Underfitting: If we try to fit a straight line to data that clearly follows a curve, our line will miss the underlying trend. It’s too simple, failing to capture the nuances of the relationship. This is underfitting.
- Overfitting: Now, imagine we draw a line that wiggles and bends to pass through every single data point exactly, including any outliers or random noise. This line perfectly fits the training data, but if we get a new data point, it’s unlikely to fall neatly onto this excessively complex curve. This is overfitting.
- A Good Fit: A well-fitted model draws a smooth curve that captures the general trend of the data without getting caught up in the noise. It generalizes well, meaning it will likely make accurate predictions for new data points.
This visual analogy is powerful because it directly relates to how our models behave. At Explore the Cosmos, we strive for that “good fit” in our analysis tools and articles, whether it’s dissecting cycling metrics or understanding complex algorithms.
Why Does Overfitting Happen?
Overfitting is a common challenge in machine learning, and it typically arises from a few key factors:
1. Model Complexity
When a model has too many parameters or is too complex relative to the size of the dataset, it has the capacity to memorize the training data. Think of a neural network with millions of parameters trying to learn from a small set of images; it’s prone to learning specific pixel arrangements rather than general object features.
2. Insufficient Training Data
A small dataset provides fewer examples for the model to learn from. When data is scarce, the model might mistake random noise or outliers for genuine patterns, leading to overfitting. This is why data augmentation—artificially increasing the size and diversity of the training dataset—is a critical technique.
3. Over-training
Training a model for too many epochs (iterations over the dataset) can lead to overfitting. Initially, the model learns valuable patterns, but as training continues, it starts to fit the noise. This is where techniques like “early stopping” come into play, halting training when performance on a validation set begins to degrade.
4. Unrepresentative Training Data
If the training data doesn’t accurately reflect the real-world data the model will encounter, it can lead to overfitting. For instance, if a computer vision model is trained only on well-lit, high-resolution images, it will struggle with blurry or dimly lit images in real-world applications.
The Impact of Overfitting: Why It Matters for Discovery
The consequences of an overfit model are significant:
- Poor Generalization: The most direct impact is a failure to perform accurately on new, unseen data. This means a model that performed brilliantly in the lab might be useless in the real world.
- Reduced Robustness: Overfit models are highly sensitive to variations in input data. Small changes can lead to wildly different and inaccurate predictions.
- Misleading Insights: If we rely on an overfit model for analysis, it can lead to flawed conclusions. For example, attributing a performance dip in cycling to a specific factor when it’s actually due to the model misinterpreting noisy data.
At Explore the Cosmos, we emphasize data-driven analysis to uncover genuine insights. An overfit model is the antithesis of this, obscuring true patterns with noise.
Preventing Overfitting: Building Robust Models
Fortunately, there are robust strategies to combat overfitting and ensure our models generalize well. These techniques are fundamental to building reliable analytical tools, whether for cycling performance or understanding complex systems.
1. Cross-Validation
This technique involves splitting the dataset into multiple subsets (folds). The model is trained on a portion of the data and validated on the remaining fold. This process is repeated multiple times, with each fold used as a validation set once. It provides a more reliable estimate of how the model will perform on unseen data.
2. Regularization
Regularization techniques add a penalty to the model’s loss function based on the complexity of the model (e.g., large coefficients). This encourages the model to be simpler and less prone to fitting noise. Common methods include L1 and L2 regularization.
3. Data Augmentation
As mentioned, increasing the diversity and size of the training dataset is crucial. For image data, this can involve techniques like rotating, flipping, cropping, or adding noise to existing images to create new training samples.
4. Early Stopping
During training, we monitor the model’s performance on a separate validation set. If the validation error starts to increase (or accuracy decreases) while the training error continues to fall, we stop the training process. This prevents the model from entering the overfitted phase.
5. Simplify the Model
Sometimes, the simplest solution is the best. Reducing the number of features, layers in a neural network, or parameters can prevent the model from becoming too complex and memorizing noise.
6. Dropout
In neural networks, dropout randomly deactivates a fraction of neurons during training. This forces the network to learn more robust features, as it cannot rely on any single neuron being available for every calculation.
Overfitting in Practice: From Space Navigation to Cycling Metrics
The principles of overfitting and its prevention are universally applicable. For our Apple Health Cycling Analyzer, imagine if a model predicting your optimal recovery time started overfitting to a few unusually strenuous rides. It might incorrectly recommend extended rest periods after every slightly challenging effort, hindering your training progress. By applying robust validation and avoiding overly complex predictive models, we ensure our tools provide actionable, reliable insights, not just memorized correlations.
Similarly, in space science, a model attempting to predict the trajectory of a new celestial object based on limited observations could easily overfit to the initial, potentially noisy, data. This could lead to inaccurate predictions of its path, with significant consequences for missions. Ensuring generalization is paramount for safe and successful exploration.
Conclusion: The Pursuit of True Understanding
Overfitting is a critical challenge in machine learning, a subtle trap where a model’s learning becomes a hindrance rather than a help. By understanding its causes and diligently applying prevention techniques like cross-validation, regularization, and early stopping, we can build models that truly learn, generalize, and provide us with the clear, actionable insights we seek. At Explore the Cosmos, this pursuit of robust, well-generalized understanding fuels our mission to empower your data-driven discoveries, whether you’re charting a course through the stars or optimizing your next ride.
Leave a Reply