If you’ve ever looked at a summary of your cycling data, a financial portfolio, or a weather report, you’ve probably been lied to by the “average.”
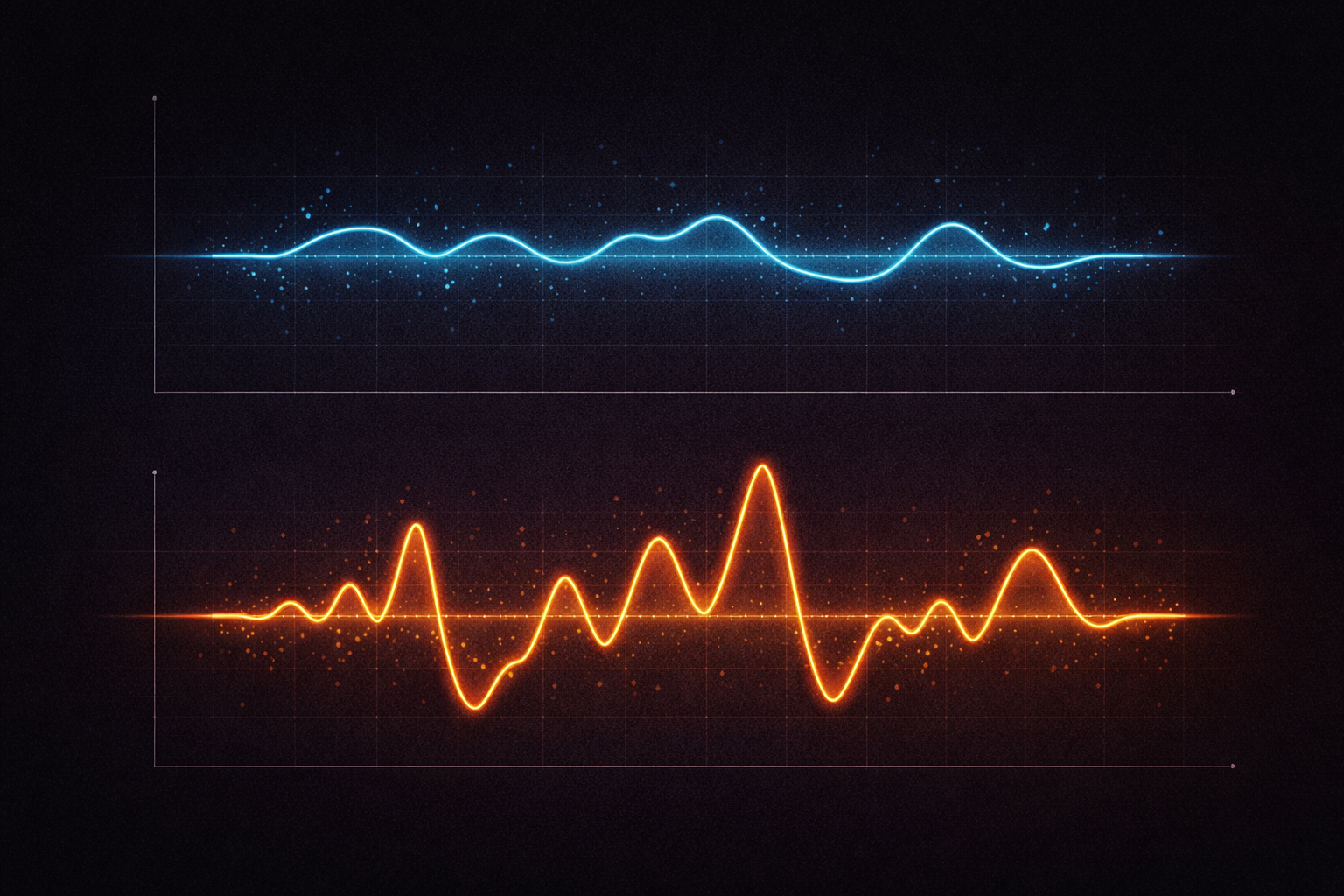
Imagine two cyclists, Rider A and Rider B. They both go out for a one-hour ride, and when they check their Apple Health cycling metrics afterward, they both see an average power output of 150 watts.
On paper, they did the exact same amount of work. But their physical experiences were entirely different.
- Rider A did a steady-state endurance ride, holding a perfectly smooth pace between 145 and 155 watts the entire time.
- Rider B did a grueling interval workout, alternating between a complete rest at 0 watts and an all-out sprint at 300 watts.
If we only look at the average (the mean), we miss the entire story. The mean tells us where the center of the data is, but it tells us absolutely nothing about how the data behaves around that center.
To understand the shape, the volatility, and the true nature of your data, you need to understand spread. And in data science, machine learning, and performance tracking, the two most important tools for measuring spread are variance and standard deviation.
In this guide, we are going to demystify these mathematical concepts in plain English. No confusing jargon – just the intuition behind how they work, why they matter, and how to apply them to everything from your heart rate data to machine learning algorithms.
What is Spread? (And Why You Should Care)
In statistics, “spread” (or dispersion) is the measure of how far your data points are scattered away from the average.
Think of a flock of birds. The average is the center of the flock. If the birds are flying tightly packed together, the spread is low. If they are flying far apart, taking up a massive section of the sky, the spread is high.
Why does this matter? Because predictability and reliability live in the spread.
If a machine learning model predicts a housing price will be $300,000, but the spread of its past errors is massive, that prediction is practically useless. If you want to increase your cycling VO₂max, you need to know if your heart rate during an interval was tightly grouped in Zone 5, or if it was widely spread across Zones 3, 4, and 5.
To measure this spread accurately, mathematicians developed variance.
What is Variance? (The Theory)
Variance is a number that tells you the average distance of every data point from the mean – but with a mathematical twist.
Let’s walk through the intuition of how variance is calculated, step-by-step. Let’s use our cyclist’s power output (in watts) as an example.
Step 1: Find the Average (The Mean)
First, you calculate the normal average. Let’s say our average is 150 watts.
Step 2: Calculate the Distance from the Mean
Next, you look at every single second of your ride and ask: “How far away is this number from 150?”
- If you pedaled at 160 watts, the distance is +10.
- If you pedaled at 140 watts, the distance is -10.
Step 3: The Problem with Negatives
Here is where we run into a mathematical wall. If we just add up all those distances to find an “average distance,” the positives (+10) and the negatives (-10) will cancel each other out. Your total spread would look like zero, which we know is false.
Step 4: Square the Distances (The Solution)
To fix the canceling-out problem, we take every single distance and multiply it by itself (we square it).
- (+10) squared becomes 100.
- (-10) squared also becomes 100.
By squaring the numbers, all distances become positive. Furthermore, squaring acts as an amplifier. It heavily punishes outliers. If a number is only 1 unit away from the mean, it stays 1 (1 x 1 = 1). But if a number is 20 units away from the mean, it blows up to 400. Variance cares deeply about wild, extreme data points.
Step 5: Average the Squares
Finally, you add up all those squared numbers and find their average. This final number is your Variance.
The Problem with Variance
Variance is an incredibly important concept in data science. It powers complex machine learning models and helps data scientists understand unstructured data.
But for you and me – looking at a spreadsheet or an Apple Watch screen – variance has a fatal flaw.
Because we squared all the numbers in Step 4, our final unit of measurement is also squared. If we were measuring watts, our variance is measured in “squared watts.” If we were looking at heart rate, the variance is in “squared beats per minute.”
What on earth is a squared watt? It’s completely meaningless to human intuition.
We need a way to undo the damage of the square, to bring our data back down to reality. Enter: Standard Deviation.
What is Standard Deviation? (The Fix)
Standard deviation is simply the square root of the variance.
That’s it. That is the big secret. You take the variance, which is trapped in confusing “squared” units, and you hit the square root button on your calculator.
This instantly converts the number back into your original units. If your variance was 100 squared watts, your standard deviation is 10 watts.
How to Read Standard Deviation
Standard deviation (often represented by the Greek letter sigma, σ) tells you the “typical” or “standard” amount that your data deviates from the average.
Let’s return to Rider A and Rider B, who both averaged 150 watts.
- Rider A (Steady endurance): Has a standard deviation of 5 watts. This tells us that most of the time, their power output was within 5 watts of the average (between 145w and 155w). Highly consistent.
- Rider B (Heavy intervals): Has a standard deviation of 120 watts. This immediately tells us the ride was incredibly volatile. The “typical” moment on the bike was nowhere near the 150w average.
Whenever you look at a dataset, the standard deviation acts as a “confidence score” for the average. A low standard deviation means you can trust the average to accurately represent the data. A high standard deviation means the average is hiding a chaotic, wide-ranging set of numbers.
Why It Matters: Real-World Applications
Understanding standard deviation isn’t just an academic exercise. It is a foundational tool for analyzing systems, human performance, and predictive algorithms. Here is how it shows up in the real world.
1. Cycling Performance and Fitness Tracking
If you export your workout data using a privacy-first tool like the Apple Health Cycling Analyzer, standard deviation is vital for tracking your progress.
When you pace yourself during a time trial or a long climb, your goal is physical efficiency. Spikes in power burn through your muscular glycogen reserves rapidly. By looking at the standard deviation of your power output or heart rate, you can measure your pacing efficiency. A lower standard deviation means a smoother, more efficient ride.
Similarly, heart rate standard deviation is used to calculate HRV (Heart Rate Variability). Unlike steady pacing, a higher standard deviation in the milliseconds between your heartbeats indicates a recovered, stress-free nervous system!
2. Machine Learning and Data Science
In the data science workflow, standard deviation is a gatekeeper. Before training a machine learning model to predict outcomes, data scientists must look at the spread of their features.
If you are feeding a neural network data about human ages (ranging from 1 to 100) alongside data about annual incomes (ranging from $20,000 to $500,000), the massive spread of the income data will mathematically overwhelm the age data. Algorithms will mistakenly assume income is more important simply because the numbers – and the standard deviations – are larger.
Data scientists use standard deviation to “scale” or normalize data, forcing all variables to have the same spread so the machine learning model can learn effectively.
3. Space Science and Astronomy
When astronomers analyze light curves from distant stars to detect exoplanets, they aren’t just looking for dimming light. Telescopes capture a lot of noise – space dust, atmospheric interference, and sensor glitches. By calculating the standard deviation of a star’s normal light output, astronomers can mathematically prove whether a dip in light is just random background noise (within standard deviation) or a genuine, statistical anomaly (a planet passing in front of the star).
Common Misconceptions About Spread
As you begin to apply these concepts to your own data, beware of these common pitfalls:
Misconception 1: “A high standard deviation is bad.”
High standard deviation is neither good nor bad; it is simply descriptive. A high standard deviation in your daily caloric intake might mean you have poor dietary discipline. But a high standard deviation in a cycling interval session means you executed the hard-easy contrasts perfectly. Context is everything.
Misconception 2: “Standard deviation is the same as the Range.”
The range is simply the absolute highest number minus the absolute lowest number. If you ride at 100 watts for 59 minutes, but sprint to 1000 watts for 1 second, your range is massive (900 watts). However, your standard deviation would still be quite low, because 99.9% of your data points are clustered tightly around 100 watts. Standard deviation accounts for all data points, whereas range only looks at the two extremes.
The Takeaway
We naturally crave simplicity. We want a single number – like an average – to summarize a complex event, a difficult workout, or an intricate dataset.
But data, much like human performance, is rarely simple.
Variance and standard deviation give us the vocabulary to understand the chaos. They allow us to see beyond the center of the data and understand its true boundaries. The next time you finish a ride, run a script, or analyze a dataset, don’t just look at the mean. Look at the spread. That is where the truth actually lives.
Leave a Reply