Think about the last time your email app sorted incoming messages into “Primary,” “Promotions,” and “Spam” – without you lifting a finger. Or the last time a music platform served up a playlist of songs you’d never heard but somehow immediately liked.
Both of those systems are powered by machine learning. But they’re powered by fundamentally different kinds of machine learning.
The first – spam filtering – learned from examples. Someone, somewhere, labeled thousands of emails as “spam” or “not spam,” and a model learned the difference. It was trained with answers.
The second – music recommendations – didn’t start with labels. It looked at millions of listening patterns, found listeners who behaved like you, and grouped them together. Nobody told it what the groups were. It found the structure on its own.
That distinction – learning with answers versus learning without them – is the core difference between supervised and unsupervised learning. And it’s one of the most important conceptual divides in all of machine learning.
This article will give you a thorough, practical understanding of both approaches: what they are, how they work, when to use each, and what they look like in the real world. No jargon without explanation. No theory without application.
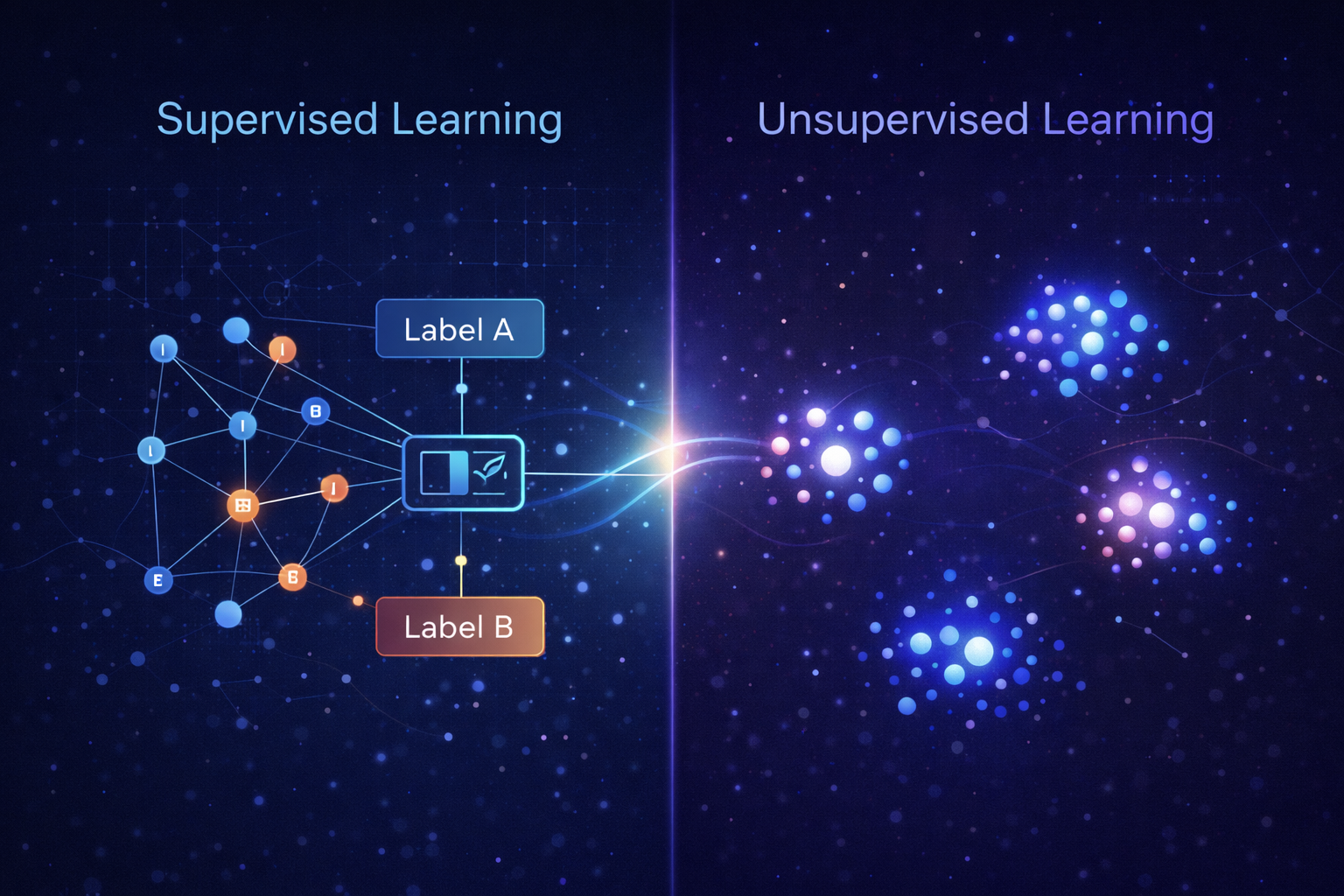
The Big Picture: Two Ways a Model Can Learn
Before going deep on either approach, here’s the clearest possible summary of the distinction:
Supervised learning: The model is trained on labeled data – examples where both the input and the correct output are known. The model learns to map inputs to outputs by studying those examples.
Unsupervised learning: The model is trained on unlabeled data – examples where only the inputs are known. The model looks for hidden structure, patterns, or groupings on its own, without being told what to find.
A useful analogy: imagine teaching a child to identify animals.
- Supervised: You show the child a picture of a dog and say, “This is a dog.” Then a cat: “This is a cat.” After enough labeled examples, the child can identify new animals correctly.
- Unsupervised: You hand the child a box of 500 animal photos with no labels and say, “Sort these into groups.” The child notices that some animals have fur, some have feathers, some are small, some are large – and begins creating clusters based on shared characteristics. Nobody told them what the groups were. They discovered the structure themselves.
Both approaches produce useful learning. They just operate with different information and answer different kinds of questions.
Part One: Supervised Learning
What It Is
Supervised learning is the most widely used branch of machine learning. In supervised learning, every training example consists of two parts:
- Input features (also called predictors or independent variables) – the information the model receives
- A labeled output (also called the target variable or dependent variable) – the correct answer for that input
The model’s job during training is to learn the relationship between inputs and outputs well enough to make accurate predictions on new, unseen inputs.
The word “supervised” comes from the idea that the model’s learning is supervised by the correct answers. It makes a prediction, compares it to the known answer, measures its error, and adjusts. This process repeats across thousands or millions of examples until the model becomes accurate.
The Two Main Types of Supervised Learning
Supervised learning problems generally fall into one of two categories, depending on the nature of the output.
Classification
The model predicts which category an input belongs to.
- Binary classification: Two possible outcomes (Yes/No, True/False, Spam/Not Spam)
- Multi-class classification: More than two possible categories (Dog/Cat/Bird, Disease A/Disease B/Healthy)
The output is a discrete label – a category, not a number.
Regression
The model predicts a continuous numerical value.
- What will this house sell for?
- How many units will we sell next month?
- What will a cyclist’s heart rate be at a given power output?
The output is a number along a scale – not a category.
How Supervised Learning Works (Simplified)
- Collect labeled data. Historical examples where both inputs and correct outputs are known.
- Split the data. Typically into a training set (to learn from) and a test set (to evaluate on data the model hasn’t seen).
- Train the model. Feed the training data into an algorithm. The model adjusts its internal parameters to minimize prediction error.
- Evaluate performance. Measure accuracy, error rates, or other metrics on the test set.
- Deploy. Apply the trained model to new, real-world inputs to generate predictions.
The quality of a supervised learning model is directly tied to the quality and quantity of the labeled data it was trained on. Garbage in, garbage out – but more specifically: mislabeled in, confused model out.
Real-World Examples of Supervised Learning
Email Spam Detection
Input: Email content, sender address, subject line, metadata
Output label: Spam or Not Spam
How it learned: Trained on millions of emails that humans (or prior systems) correctly labeled
Every time you mark an email as spam or “not spam,” you’re contributing labeled data that improves the model.
Medical Diagnosis from Imaging
Input: MRI or CT scan image
Output label: Malignant / Benign / Healthy (or a probability score)
How it learned: Trained on thousands of scans labeled by radiologists
This is one of the highest-stakes applications of supervised learning. The model learns the visual patterns associated with different diagnoses – patterns too subtle and numerous for humans to manually encode as rules.
Credit Risk Assessment
Input: Income, credit history, debt-to-income ratio, employment status, loan amount
Output label: Low risk / Medium risk / High risk (or probability of default)
How it learned: Trained on historical loan data where actual outcomes (repaid vs. defaulted) are known
Lenders use these models to make faster, more consistent decisions than manual underwriting alone.
Cycling Performance Prediction
Input: Power output, cadence, heart rate, temperature, elevation, ride duration
Output label: Predicted efficiency factor, fitness score, or recovery recommendation
How it learned: Trained on labeled ride data where performance outcomes are known
For cyclists using tools like the Apple Health Cycling Analyzer, supervised learning concepts underpin many of the relationships between training load and measurable performance outputs.
House Price Estimation
Input: Square footage, location, number of bedrooms, age of property, nearby amenities
Output label: Sale price (in dollars)
How it learned: Trained on historical property sales data
This is a classic regression problem – the model outputs a number, not a category.
When Supervised Learning Is the Right Choice
Supervised learning is well-suited when:
- You have a clear, measurable target variable (what you’re trying to predict)
- You have historical labeled examples – past instances where the input and correct output are both known
- You need to make predictions about new, unseen data
- The relationship between inputs and outputs is learnable from historical patterns
The main constraint: labeled data is expensive. Creating it requires human time, domain expertise, and in some cases, specialized knowledge (medical labeling, legal classification). This is one of the primary reasons unsupervised learning exists.
Part Two: Unsupervised Learning
What It Is
Unsupervised learning removes the labeled output entirely. The model receives only inputs – no correct answers, no predefined categories, no target variable. Its job is to find structure, patterns, or organization within the data on its own.
This sounds more abstract than supervised learning – and it is. But it’s also extraordinarily powerful in situations where you don’t know in advance what you’re looking for, or where creating labeled data would be impractical.
The model isn’t evaluated on whether it gets the “right answer” (there’s no right answer defined). Instead, it’s evaluated on whether the structure it discovers is meaningful, useful, and consistent.
The Two Main Types of Unsupervised Learning
Clustering
The model groups data points into clusters based on similarity – without being told what the groups should be or how many there should be.
Points within the same cluster are more similar to each other than to points in other clusters. The model defines similarity mathematically, based on distance or statistical relationships between data points.
Common clustering algorithms: K-Means, DBSCAN, Hierarchical Clustering
Dimensionality Reduction
Real-world datasets often have dozens, hundreds, or even thousands of variables (features). Dimensionality reduction compresses that complexity into fewer variables – while preserving as much of the meaningful structure as possible.
This is used for visualization, noise reduction, and as a preprocessing step before other models are applied.
Common dimensionality reduction methods: PCA (Principal Component Analysis), t-SNE, UMAP
There are other unsupervised techniques (anomaly detection, generative models, association rule mining), but clustering and dimensionality reduction are the two most commonly encountered in applied settings.
How Unsupervised Learning Works (Simplified)
- Collect unlabeled data. Raw inputs with no associated output labels.
- Choose a method. Clustering, dimensionality reduction, or another unsupervised approach based on the goal.
- Run the algorithm. The model analyzes the data, finds structure, and produces an output – cluster assignments, compressed representations, anomaly scores.
- Interpret the results. A human expert examines the discovered structure and determines whether it’s meaningful and actionable.
- Apply the insights. Use the discovered patterns to inform decisions, downstream models, or further analysis.
Step 4 is critical and often overlooked: unsupervised learning produces structure, but humans must interpret whether that structure is useful. A clustering algorithm will always produce clusters – whether those clusters are meaningful is a separate question.
Real-World Examples of Unsupervised Learning
Customer Segmentation
Input: Purchase history, browsing behavior, demographics, engagement frequency
No labels: Nobody pre-defined what the customer segments should be
What the model finds: Natural groupings – perhaps “high-value infrequent buyers,” “budget-conscious regulars,” “lapsed customers,” and “new experimenters”
How it’s used: Marketing teams tailor messaging and offers to each segment
This is one of the most common business applications of unsupervised learning. The company didn’t know in advance how many meaningful customer types existed – the data revealed it.
Anomaly Detection in Network Security
Input: Network traffic patterns – volume, timing, source, destination, protocol
No labels: Normal traffic isn’t explicitly labeled; anomalies aren’t pre-defined
What the model finds: Clusters of “normal” behavior; data points that fall outside those clusters are flagged as anomalies
How it’s used: Cybersecurity teams investigate flagged activity for potential intrusions
The model doesn’t know what an attack looks like. It knows what “normal” looks like – and flags everything that deviates significantly.
Genomics and Biological Research
Input: Gene expression data across thousands of genes and samples
No labels: Researchers don’t know in advance which genes cluster together functionally
What the model finds: Groups of genes that behave similarly, potentially revealing functional relationships or disease mechanisms
How it’s used: Guides further biological research and hypothesis generation
Unsupervised learning has become a critical tool in genomics precisely because there are no pre-existing labels for most gene expression patterns – the science is discovering them.
Topic Modeling in Text Analysis
Input: Thousands of news articles, reviews, or documents – raw text
No labels: Nobody categorized the documents in advance
What the model finds: Latent topics – groups of words that tend to appear together, representing underlying themes
How it’s used: Content organization, trend analysis, research summarization
A media company processing ten years of news articles doesn’t hand-label every story. Unsupervised topic modeling surfaces the themes automatically.
Exploratory Cycling Data Analysis
Input: Ride data across hundreds of sessions – heart rate, power, duration, elevation, temperature
No labels: No pre-defined ride categories
What the model finds: Natural clusters of ride types – perhaps recovery rides, threshold efforts, long endurance rides, and sprint sessions – based purely on the data patterns
How it’s used: Helps athletes and coaches understand their actual training distribution, separate from how rides were manually tagged
When Unsupervised Learning Is the Right Choice
Unsupervised learning is well-suited when:
- No labeled data exists – and creating it would be impractical or impossible
- You want to explore data structure before committing to a specific question
- You’re looking for unknown patterns – you don’t know in advance what categories or groups exist
- You need to reduce complexity in high-dimensional data for visualization or downstream modeling
- The goal is discovery, not prediction
The main challenge: results require human interpretation. Unlike supervised learning where accuracy can be measured objectively, the “quality” of unsupervised learning outputs is partly subjective – did the discovered structure reveal something genuinely useful?
Supervised vs. Unsupervised: Side-by-Side Comparison
| Dimension | Supervised Learning | Unsupervised Learning |
| Training data | Labeled (input + correct output) | Unlabeled (input only) |
| Goal | Predict a known output type | Discover hidden structure or patterns |
| Output type | Prediction (category or number) | Clusters, compressed representations, anomaly scores |
| Evaluation | Objective metrics (accuracy, error rate) | Requires human interpretation |
| Data requirement | Labeled data – often expensive to create | Raw data – usually easier to collect |
| Primary use cases | Classification, regression, forecasting | Segmentation, exploration, compression |
| When to use | When you know what you’re predicting | When you’re discovering what exists |
| Example | Spam detection, medical diagnosis | Customer segmentation, topic modeling |
The Gray Zone: Semi-Supervised and Self-Supervised Learning
Reality rarely fits perfectly into two clean boxes. In practice, many modern ML systems blend both approaches.
Semi-supervised learning uses a small amount of labeled data combined with a large amount of unlabeled data. This is valuable when labeling is expensive but unlabeled data is abundant. The model learns from the labeled examples first, then uses the structure of the unlabeled data to refine its understanding.
Self-supervised learning – the approach behind many large language models and modern AI systems – generates its own labels from the structure of the data itself. A language model trained to predict the next word in a sentence is technically supervised (the “label” is the next word), but no human labeled those examples. The data labels itself.
These hybrid approaches have become increasingly important as AI systems scale. But understanding pure supervised and unsupervised learning first is essential context for making sense of them.
Choosing the Right Approach: A Decision Framework
When approaching a new ML problem, these questions will guide you toward the right category:
Start here:
→ Do you have a clearly defined output you’re trying to predict?
- Yes → Supervised learning. Is the output a category or a number? That determines classification vs. regression.
- No → Unsupervised learning. What are you looking for? Groupings? Structure? Anomalies?
Follow-up questions for supervised learning:
- Do you have historical labeled examples?
- Is there enough labeled data to train reliably?
- Is the pattern learnable from past data?
Follow-up questions for unsupervised learning:
- What would a meaningful discovery look like?
- How will you validate that the discovered structure is real and useful?
- Who will interpret the results – and do they have the domain expertise to evaluate them?
Two Sides of the Same Discipline
Supervised and unsupervised learning are not rivals. They’re complementary tools within the same discipline, each designed to answer different kinds of questions.
Supervised learning is the workhorse of applied ML – powerful, measurable, and dominant in production systems across industries. It thrives when you know what you’re predicting and have the labeled history to support it.
Unsupervised learning is the explorer – essential when the structure of the data itself is unknown, when labeling is impractical, or when the goal is discovery rather than prediction. It reveals what you didn’t know to ask about.
The sharpest practitioners in machine learning aren’t those who favor one over the other. They’re those who understand both well enough to know which question they’re actually trying to answer – and then choose the right tool for it.
Leave a Reply